(Last Updated On: January 18, 2021)
When dealing with paper documents, searching the file in a heap of papers is like trying to find a needle in a bundle of hay. There is no point wasting your precious time on worthless deeds. This is why going paperless is a necessity. The way to do so is to scan papers and get their electronic versions in PDF format. Scanned PDF documents are much easier to manage. But everything has advantages and disadvantages. Scanned PDFs are image-based, which means their text is not editable. Modifying the content of these PDFs would be a headache. Needless to say, you don’t want to type all words in the documents by hand. Is there a solution to avoid the task of retyping? Fortunately, the answer is yes. We have the OCR technology that recognizes the text in images and turns it into machine-readable text. In this article, I will walk you through two pieces of online PDF OCR software that help you convert the scanned PDF to an editable file.
#1. Sejda
Sejda is a web-based PDF OCR tool to convert PDF scans to searchable PDFs or plain text files.
There are several different ways for you to upload your scanned PDF. Drop your PDF onto the web page. Browse your files and select the PDF through the file browser. Provide the URL of your PDF. Or connect Sejda to your cloud storage and import the PDF from Google Drive, Dropbox, or One Drive. Be rest assured your file stays private since it is transferred over an encrypted SSL connection. What’s more, your file will be permanently deleted from the server 2 hours after the conversion. It is no exaggeration to say you can expect a super-fast OCR process. In my test, Sejda converted a 1MB scanned PDF to a text file within less than half a minute. Besides, you can get a satisfying converted result even though Sejda claims not to guarantee 100% OCR accuracy.
A notable feature of Sejda is the single page mode. You can instruct the program to recognize the text on a specific PDF page you choose. When the OCR process is done, you can copy the text to the clipboard and save it to your computer.
In my opinion, Sejda is a reliable PDF to text OCR converter and worth giving a shot. You can use it for free but the free service it offers has some limitations on usage. The maximum file upload size can not exceed 50 MB. The number of pages of the PDF to be uploaded can not be more than 10. Only 3 tasks are allowed to be processed per hour. To lift these limits, shell out $7.5 to subscribe as a monthly premium user.
- Drag and drop your PDF anywhere on the page. Or click on “Upload PDF file” to choose your PDF.
- When the PDF is uploaded to the server, a panel shows up.
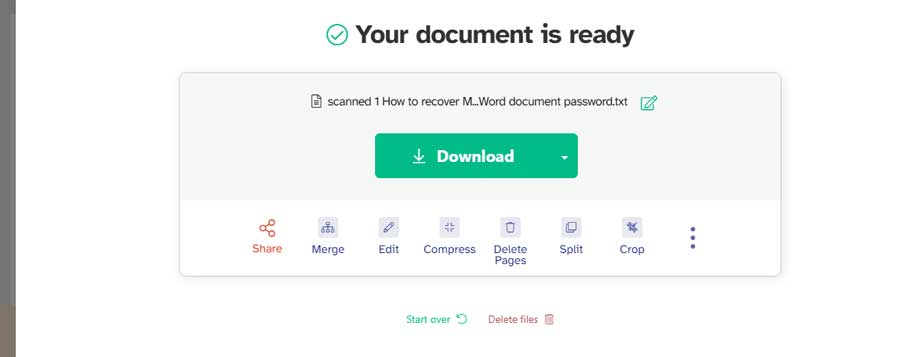
- To OCR a specific PDF page, go to the right-side pane, select the language and press “Recognize the text on this page”. You will see the editable text on the right pane when it is converted from the scanned PDF page.
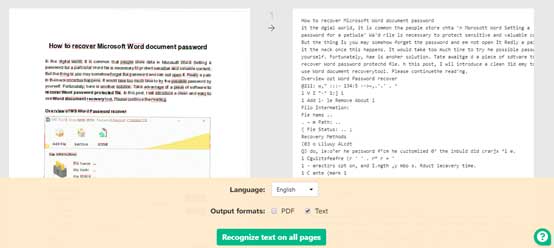
- To OCR the entire PDF document, go to the bottom of the panel, select the language, choose “Text”, and press “Recognize text on all pages”. When your scanned PDF is converted to the text file, you will see the big green “Download” button on the screen.
#2. PDF OCR Online
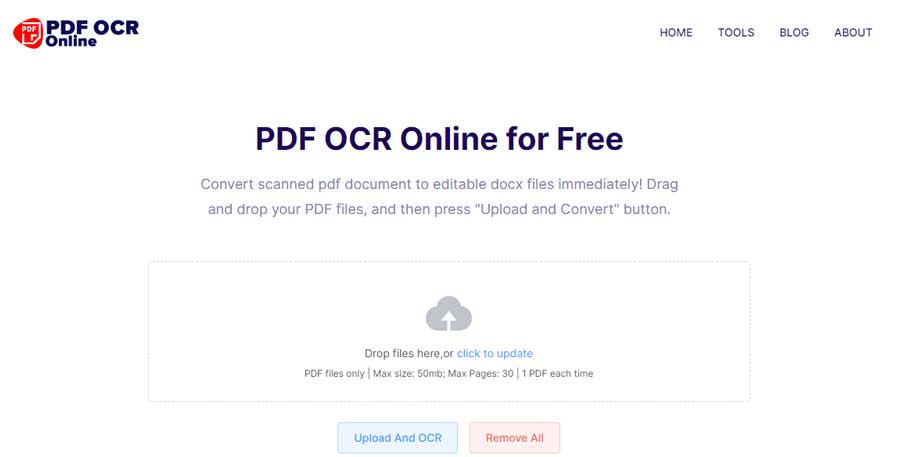
PDF OCR Online is another browser-based PDF OCR utility. It is specialized in converting the scanned PDF to a Word document. The exported file format is DOCX. If you want to OCR PDF to DOCX, PDF OCR Online is a go-to option.
The application lets you upload a PDF with a size of no more than 50MB and up to 30 pages. Believe it or not, PDF OCR Online provides the fastest PDF to Word OCR conversion. Tests indicate a 1MB scanned PDF is converted to a .docx file within a few seconds. As PDF OCR Online promises, neither words nor layout in the original file will be changed after the conversion. Your file will be erased from its server after 12 hours. A nifty feature of PDF OCR online is the email notification. You can provide an email address to receive the download link. Thus, you don’t have to wait for the completion of the conversion. Frankly speaking, I like PDF OCR Online because of its ease of use and speedy OCR performance. BTW, PDF OCR Online is totally free for use.
- Drop your PDF into the drop box. You can either click on “Click to upload” to select your PDF.
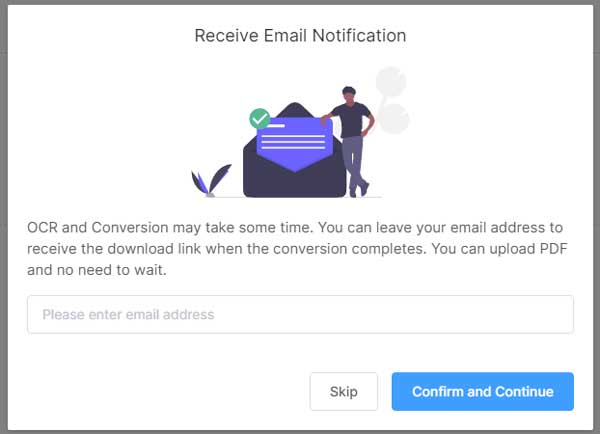
- Press “Upload and OCR”. The email notification dialog pops up.
- Enter an email address and click on “Confirm and Continue”. Or click on “Skip”.
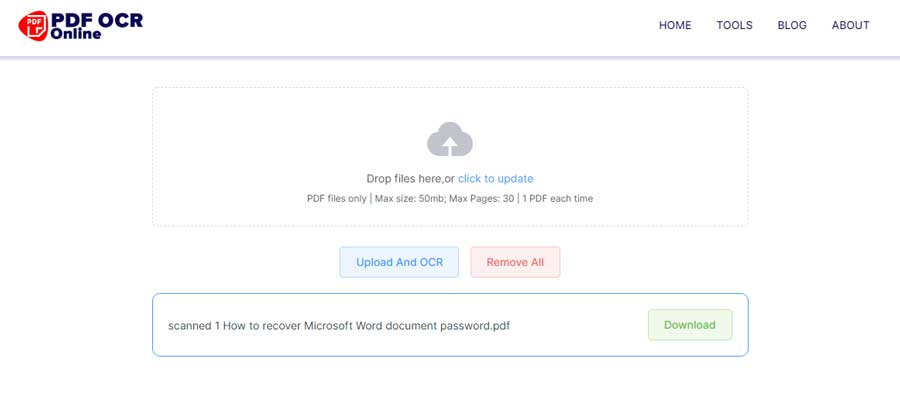
- The conversion starts as soon as the PDF is uploaded to the server.
- Wait for a while and you will get the download link.
Conclusion
Scanning papers to get scanned PDF documents is necessary for better document management. But it is a pain in the neck when it comes to retyping the text in scanned PDFs for modifying the file content. By leveraging the two PDF OCR tools mentioned above, you can extract the text from scanned PDFs and convert it to text-editable files. Thus, you don’t have to type each word to make a whole new file. If you are encountering difficulty on scanned PDF editing, make good use of them to cut down unnecessary paperwork.